
ランダムフォレストモデルでの予測と実績が大きく乖離していた

作ったランダムフォレスト予測モデルで実データを元に予測してみた
日...
zaitaku-tushin.com
2025.03.25
気象データと電力消費量の相関係数を出してみる
# ファイルを再読み込み
import pandas as pd
import matplotlib.pyplot as plt
# データ読み込み
df = pd.read_csv("/mnt/data/daily_weather_and_power_consumption.csv")
# 数値変換("date"以外)
for col in df.columns:
if col != "date":
df[col] = pd.to_numeric(df[col], errors="coerce")
# 欠損値補完
df_filled = df.fillna(0)
# 相関係数を算出(目的変数との関係)
correlations = df_filled.corr(numeric_only=True)["power_consumption(kWh)"].drop("power_consumption(kWh)")
# 可視化
plt.figure(figsize=(10, 5))
correlations.sort_values().plot(kind="barh")
plt.title("各特徴量と電力消費量の相関係数")
plt.xlabel("相関係数")
plt.tight_layout()
plt.show()
correlations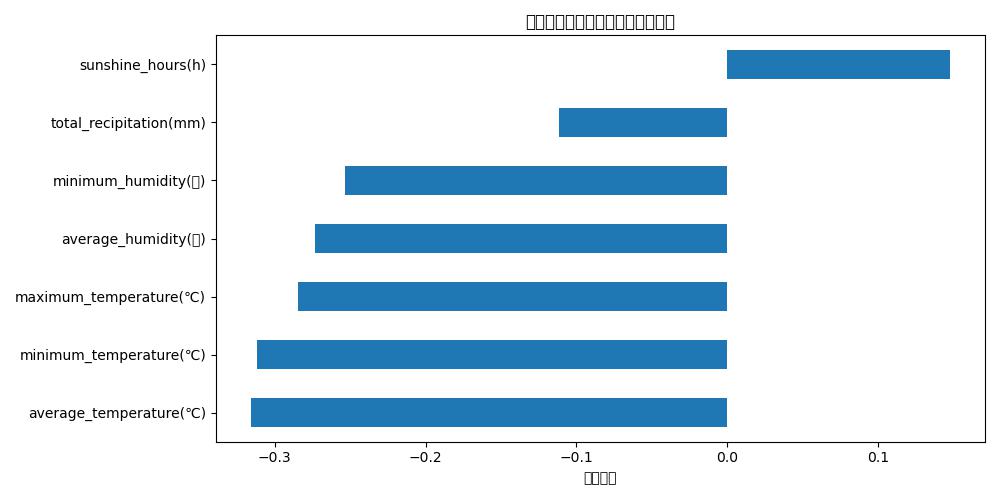
各特徴量と電力消費量の相関係数
| 特徴量 | 相関係数(r) | 備考 |
|---|---|---|
average_temperature(℃) |
-0.32 | やや強い負の相関(気温が高いと消費が下がる) |
minimum_temperature(℃) |
-0.31 | 上とほぼ同様 |
maximum_temperature(℃) |
-0.28 | 同様の傾向 |
average_humidity(%) |
-0.27 | 湿度もやや逆相関 |
minimum_humidity(%) |
-0.25 | 同上 |
total_recipitation(mm) |
-0.11 | 相関はほぼ弱い |
sunshine_hours(h) |
+0.15 | 少しだけ正の相関(光が多いと消費増) |
「total_recipitation(mm)」(降水量合計)は消費電力に対して相関関係が弱い模様。
重要度ランキングを出してみる(feature_importances_)
学習済みモデルから電力消費量を予測するにあたって、各気象データの重要度を可視化する。
# アップロードされたファイルを使って再実行
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
import joblib
model = joblib.load("models/power_predictor_model_retrained.joblib")
# 特徴量と目的変数の分離
feature_cols = [
"total_recipitation(mm)",
"average_temperature(℃)",
"maximum_temperature(℃)",
"minimum_temperature(℃)",
"average_humidity(%)",
"minimum_humidity(%)",
"sunshine_hours(h)"
]
# 重要度の抽出と可視化
importances = model.feature_importances_
importance_df = pd.DataFrame({
"feature": feature_cols,
"importance": importances
}).sort_values(by="importance", ascending=True)
# 棒グラフで可視化
plt.figure(figsize=(10, 6))
plt.barh(importance_df["feature"], importance_df["importance"])
plt.xlabel("Importance")
plt.title("特徴量の重要度(Random Forest)")
plt.tight_layout()
plt.show()
importance_df.sort_values(by="importance", ascending=False)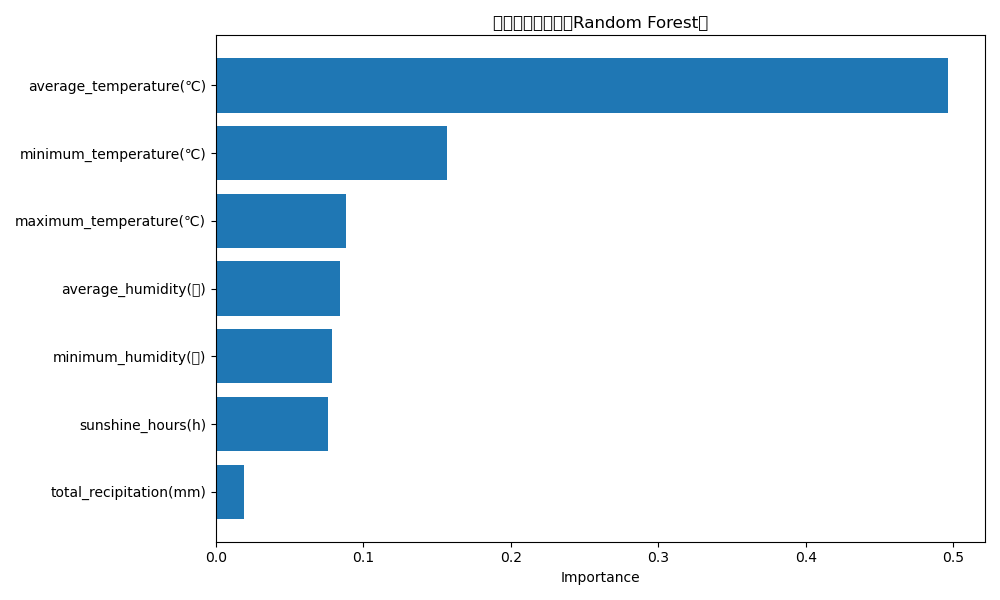
特徴量の重要度(高い順)
| 特徴量 | 重要度(寄与度) |
|---|---|
average_temperature(℃) |
0.497(全体の約50%) |
minimum_temperature(℃) |
0.157 |
maximum_temperature(℃) |
0.088 |
average_humidity(%) |
0.084 |
minimum_humidity(%) |
0.079 |
sunshine_hours(h) |
0.076 |
total_recipitation(mm) |
0.019(最も低い) |
こちらでも「total_recipitation(mm)」(降水量合計)は消費電力に対して重要度が弱い模様。
モデルの精度を上げるためにこれを削除して再度モデルを作ってみる。


コメント